
My childhood gaming group has been playing (but has not completed) Warhammer 40k: Rogue Trader.
We noticed that the items mentioned on public facing wikis often seem outdated or just incorrect. So two of us, Warren and myself, decided to see if we could use a free weekend to vibecode a wiki derived directly from the game.
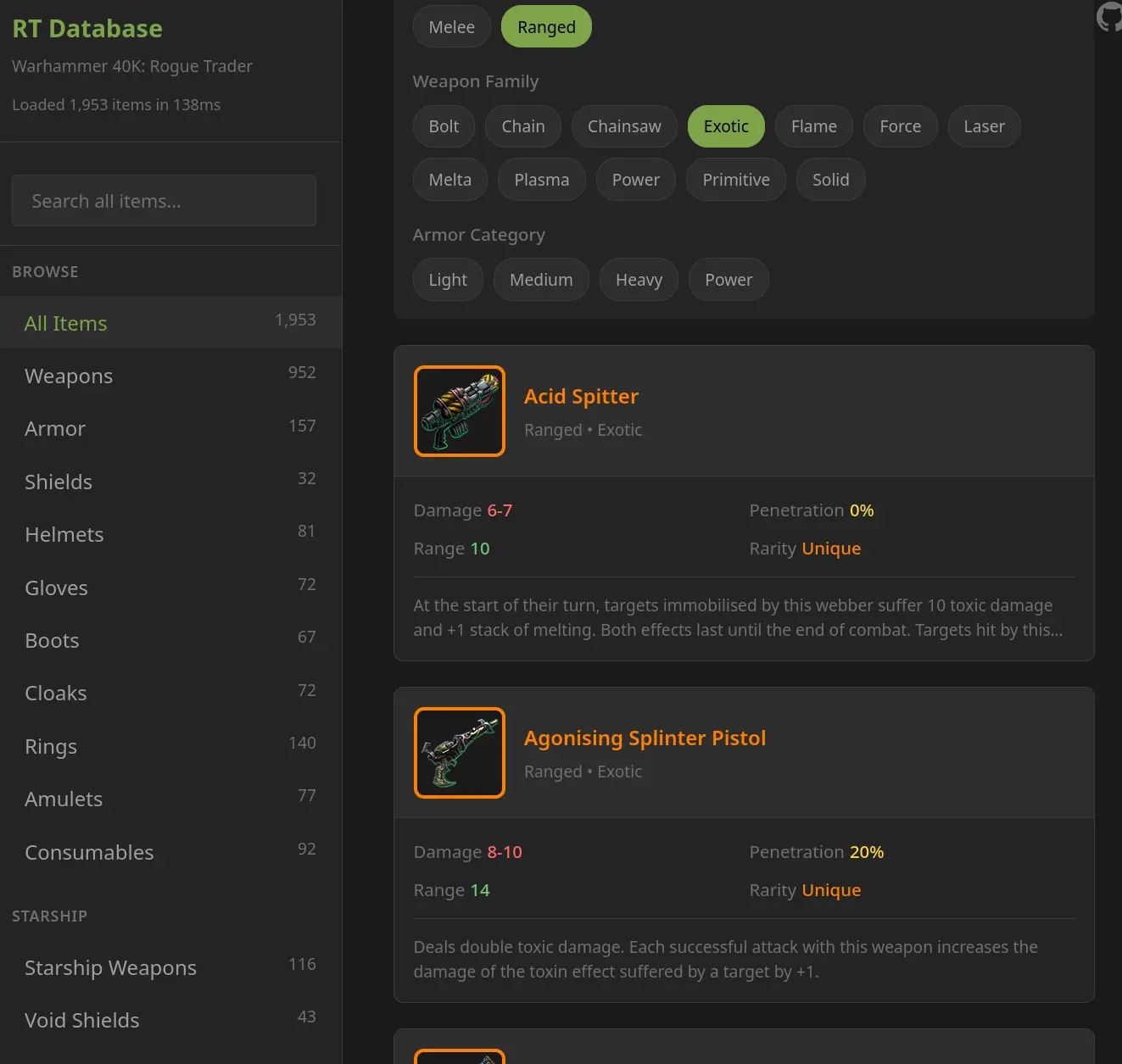
In total, it took us about 5 hours to put together our own item wiki almost entirely through vibecoding.
The meat of the problem was getting the item database from the game. As a starting point, we just scanned through the list of files and found a rather likely "blueprint" file (.jbp). A blueprint file is a JSON file that lists all the in game assets, looking at it in a hex editor it seemed like a good place to start.
Now, I was convinced that we needed to write a parser to parse this file, put together the uuids to actual art assets, and then go from there. We spent about 30 minutes on that. However, Warren thought it might actually be easier to write a mod using their mod tools that would allow us to parse the running game itself. We were not sure which approach would actually be better, so initially I walked down the path of the parser and he walked down the path of the mod.
At some point, he got the mod to at least install correctly. I am eliding over a huge number of times that he basically made some changes to the mod, reloaded the game, and then attempted to load the mod in the game. But it eventually worked! This was a real win as we discovered that 40KRT is a Unity game written in C#. This is wonderful as it means that we can use introspection on most objects. Now I don't really get how the [namespace|object graph|whatever] system in C# actually works, but it allowed us to ask for all the objects at root and then recursively walk down the object graph. There was some confusion about getting the references in objects as we kept getting empty caches, but we did some sort of thing that forced them to be realized (I forgot how), and then we had a tree of all the objects in the system. We then added an http server to our mod so that we could make restful request to our running server from our LLM, which certainly helped in walking the tree (both for us and for it). We then had the LLM just poke around until it found what looked like the items. It was able to capture the items and then we wrote it into a giant json file.
Concurrently, we built a site that actually hosts this data. I remember once reading about mcmaster.com and how their site is legendarily fast because they just put everything in a single file. So we did the same thing for our site. You just download the "large" (185k compressed) items.json file at load, and then every interaction (search, filter, ordering) you do afterwards is just client side. You do of course load images dynamically as needed, but I am still impressed by how often the "just give them everything at the start" philosophy of web development works.
The final section was taking the texture data for the items and projecting them (I am not clear on all this) so that we could view them as images. I then looped it all together to include the images in the site.
I was impressed that we were able to build a working item wiki of a video game based on "live" (running game) information in just half a working day. As an observation, I think that with LLM assisted coding, having a diverse team may be more important than ever. Part of the reason we were able to accomplish what we did is that we both are rather different types of programmers (I am web/CRUD/startups, he is computer graphics). The fact that we had different ideas about how to do different things was actually quite beneficial, as experimentation is cheap when you are using vibecoding, and the LLM is tireless in trying out different paths. LLMs do have endurance, but they don't have much taste. Pairing LLMs with a group of people with "reified" (though perhaps divergent) sensibilities allows for the pairing of their infinite endurance with humans' earned experience. It was fun!